Cortex Simulation
0. Introduction
This section of the tutorial provides step-by-step guidance on training the cortex model from scratch, and visualizing the learned internal percepts.
To get most out of this tutorial, let’s start training your first cortex model from scratch! From your root directory (i.e. ./Matisse/), run the following script:
python train.py -f Sandbox
This will start training the lightweight cortex model, which we call Sandbox model. Depending on your computational resource, the training time varies. We will come back and analyze this in the later section!
By the end of this tutorial, you will be able to:
Train the cortex model from scratch, and
Visualize the learned internal percepts.
1. Cortex model overview
The codebase for the cortex simulation is located under Simulated/Cortex. It is organized to facilitate ease of use, modification, and understanding. Below is the general structure of the directory:
Directory Structure
Simulated/CortexCortexModel.py(Main class)Modules for the cortex simulation:
C_cone_spectral_typefolderD_demosaicingfolderM_global_movementfolderP_cell_positionfolderW_lateral_inhibition_weightsfolder
In CortexModel.py, the CortexModel class is defined, as it follows:
class CortexModel(nn.Module):
def __init__(self, params):
super(CortexModel, self).__init__()
self.C_cone_spectral_type = create_C_cone_spectral_type(params)
self.D_demosaicing = create_D_demosaicing(params)
self.M_global_movement = create_M_global_movement(params)
self.P_cell_position = create_P_cell_position(params)
self.W_lateral_inhibition_weights = create_W_lateral_inhibition_weights(params)
... rest of the code ...
# Decode the optic nerve signal to the internal percept
def decode(self, ons):
pa = self.W_lateral_inhibition_weights.deconvolve(ons)
C_injected_pa = self.C_cone_spectral_type.C_injection(pa)
ip = self.D_demosaicing.demosaic(C_injected_pa)
return ip
# Encode the internal percept back to the optic nerve signal
def encode(self, ip):
pa = self.C_cone_spectral_type.C_sampling(ip)
ons = self.W_lateral_inhibition_weights.convolve(pa)
return ons
The decode and encode functions are the core functions of the cortex model, and they are used to decode the optic nerve signal to the internal percept, and encode the internal percept back to the optic nerve signal.
The main objective function of the cortical model is to minimize the signal prediction error between the predicted optic nerve signal and the ground truth optic nerve signal.
So given two optic nerve signals at two different timesteps, the CortexModel object would:
Decode the optic nerve signal at timestep 1 to the internal percept,
Translate the internal percept to the next timestep, based on the predicted global movement of the eye,
Encode the translated internal percept back to the domain of the optic nerve signal, and
Finally, compute the difference between the predicted optic nerve signal and the ground truth optic nerve signal at timestep 2.
This idea is well illustrated in our supplementary video to the paper at 4:40.
But for now, setting the technical details aside, let’s dive into the actual training procedure.
2. Training the cortex model
First and foremost, here we provide two variants of the cortex model:
The default cortex model, which is heavy-weight and trained with a realistic trichromatic retina model.
The sandbox cortex model, which is lightweight and trained with a simplified retina model.
To run the training script, from the root directory of the codebase, you can run the following command:
python train.py -f Sandbox # for the sandbox model
python train.py -f Default/LMS # for the default model
For the default model, you would need to download the NTIRE dataset as instructed here.
The default cortex model is what we used and reported in the paper, and the main reason why we are introducing the sandbox model here is to invite you to play around with the cortex model without the need of a heavy computational resource. For your reference, the approximate training time of these models are as follows:
Model Type |
NVIDIA 4090 GPU |
Apple Silicon |
CPU |
|---|---|---|---|
Sandbox |
7 minutes |
30 minutes |
2 hours |
Default |
2 hours |
24 hours |
50 hours |
The reason why the sandbox model is lightweight is because it only simulates the spectral sampling of the retina and ignores the spatial sampling and the lateral inhibition. Additionally, the scale of the simulation is reduced to 64x64 cells, whereas the default model is simulated with 256x256 cells.
The detailed difference between the two models is most clearly illustrated in these yaml files:
Let’s take a deep dive into this yaml format!
2.1. Default parameters for training the default cortex model
First and foremost, we rely on the yaml file to define all the parameters for the cortical learning simulation.
Our default yaml file for training the cortex model with a trichromatic retina is located at Experiment/Config/Default/LMS.yaml, and here is the snippet of the file:
Experiment:
name: 'LMS'
simulation_size: 256 # Dimension of the simulation (i.e. 256 for 256x256 cells)
timesteps_per_image: 2 # Number of timesteps per image (i.e. 2 for timesteps t1 and t2)
simulating_tetra: false # Whether to simulate tetrachromacy
# Retinal model parameters
RetinaModel:
.. structurally same as the default retina model in the previous tutorial ..
# Cortical model parameters
CorticalModel:
cortex_learn_eye_motion:
type: 'Default' # Learning strategy for eye motion in the cortex
cortex_learn_spatial_sampling:
type: 'Default' # Learning strategy for spatial sampling in the cortex
cortex_learn_cone_spectral_type:
type: 'Default' # Learning strategy for cone spectral type in the cortex
cortex_learn_demosaicing:
type: 'Default' # Learning strategy for demosaicing in the cortex
cortex_learn_lateral_inhibition:
type: 'Default' # Learning strategy for lateral inhibition in the cortex
latent_dim: 8 # Latent dimension (N in the paper) for the cortical model
# Training parameters
Training:
learning_rate: 0.001 # Learning rate for the optimizer
learning_progress_logging: true # Enable logging of learning progress
logging_mode: 'Local' # Mode of logging ('Local', 'Tensorboard', 'Comet')
logging_cycle: 1000 # Frequency of logging in terms of gradient updates
max_gradient_updates: 100000 # Maximum number of gradient updates for training
... rest of the parameters ...
Here, we are using the default modules for the cortex model, as type: 'Default'.
For example, this snippet:
cortex_learn_cone_spectral_type:
type: 'Default'
would instantiate the default cone spectral type module, as defined in Simulated/Cortex/C_cone_spectral_type/C_Default.py.
This command will instantiate both the retina and cortex models, based on the set parameters in the yaml file, and start the training simulation.
You would find the learned weights of the cortex model in the Experiment/LearnedWeights/{NAME_OF_EXPERIMENT} directory. Assuming that you are training the sandbox model, you will see the folder called Sandbox under LearnedWeights folder.
We are providing the multiple logging modes for the training simulation, as logging_mode: 'Local', 'Tensorboard', and 'Comet'.
You can choose the one that suits your needs, but for Comet option, you would need to create an account on Comet and store .comet.config file in the root directory of the codebase.
If the logging mode is set to 'Local', you would find the learning progress in the Experiment/Logging/{NAME_OF_EXPERIMENT} directory.
2.2. Training a sandbox model
Our sandbox model is designed to be a lightweight version of both the retina and cortex models. The main difference between the sandbox retina model and the default retina model is that the sandbox model only simulates the spectral sampling of the retina and ignores the spatial sampling and the lateral inhibition. Similarly, the sandbox cortex model only learns the spectral indetity of each cone type in the retina, and uses the ground truth eye motion value and thus skips the learning of eye motion in the cortex. The scale of the simulation is reduced to 64x64 cells, whereas the default model is simulated with 256x256 cells.
3. Visualizing the learned internal percepts
After the cortex model is updated for max_gradient_updates times, the code will terminate the training simulation, and you are then set to visualize the learned progress.
In this section, we will demonstrate how to load the pre-trained cortex model, and visualize the learned internal percepts.
First, we show how to initialize both the retina and cortex models.
import torch
import pickle
from root_config import DEVICE, ROOT_DIR
from Simulated.Retina.Model import RetinaModel
from Simulated.Cortex.Model import CortexModel
# Load the default parameters for the trichromatic retina simulation
with open(f'{ROOT_DIR}/Experiment/Config/Default/LMS.yaml', 'r') as f:
params = yaml.safe_load(f)
# Initialize the retina model
retina = RetinaModel(params).to(DEVICE)
# Initialize the cortex model
cortex = CortexModel(params).to(DEVICE)
The input to the cortex’s decode function is the optic nerve signal, which is the output of the retina simulation.
Here we use the same example image as in the previous tutorial to generate the optic nerve signal.
# You can change the example_image_path to the path of your own image
example_image_path = f'{ROOT_DIR}/Tutorials/data/sample_sRGB_image.png'
example_sRGB_image = load_sRGB_image(example_image_path, params)
# retina.CST (color space transform) is used to convert the color space
# In this case, we convert the sRGB image to linsRGB, and then to LMS
example_linsRGB_image = retina.CST.sRGB_to_linsRGB(example_sRGB_image)
example_LMS_image = retina.CST.linsRGB_to_LMS(example_linsRGB_image)
example_LMS_image = example_LMS_image.unsqueeze(0).permute(0, 3, 1, 2)
with torch.no_grad(): # gradient computation is not needed for retina simulation
list_of_retinal_responses = retina.forward(example_LMS_image, intermediate_outputs=True)
optic_nerve_signals = list_of_retinal_responses[0]
Next, we decode the optic nerve signal to the internal percept.
num_gradient_updates = 100000
# Load the pre-trained weights for the default cortex model
cortex.load_state_dict(torch.load(f'{ROOT_DIR}/Experiment/LearnedWeights/LMS/{num_gradient_updates}.pt', weights_only=True, map_location=DEVICE))
warped_internal_percept = cortex.decode(optic_nerve_signals)
# internal percept is N-channel image, where N is the latent dimension (N is formally defined in the paper)
# We use the ns_ip module (neural scope for internal percept) to project the percept to the linsRGB space
warped_internal_percept_linsRGB = cortex.ns_ip.forward(warped_internal_percept)
# Then we use the retina.CST (color space transform) to convert the linsRGB space to the sRGB space
warped_internal_percept_sRGB = retina.CST.linsRGB_to_sRGB(warped_internal_percept_linsRGB)
# get_unwarped_percept is a helper function defined in the ipython notebook file
internal_percept_sRGB = get_unwarped_percept(warped_internal_percept_sRGB, cortex)
Here internal_percept_sRGB is the learned internal percept, projected to the sRGB space, after the cortex model is trained for num_gradient_updates=100000 times.
If we vary the num_gradient_updates value, we can visualize the learned internal percepts at different stages of the training, and here is the example:
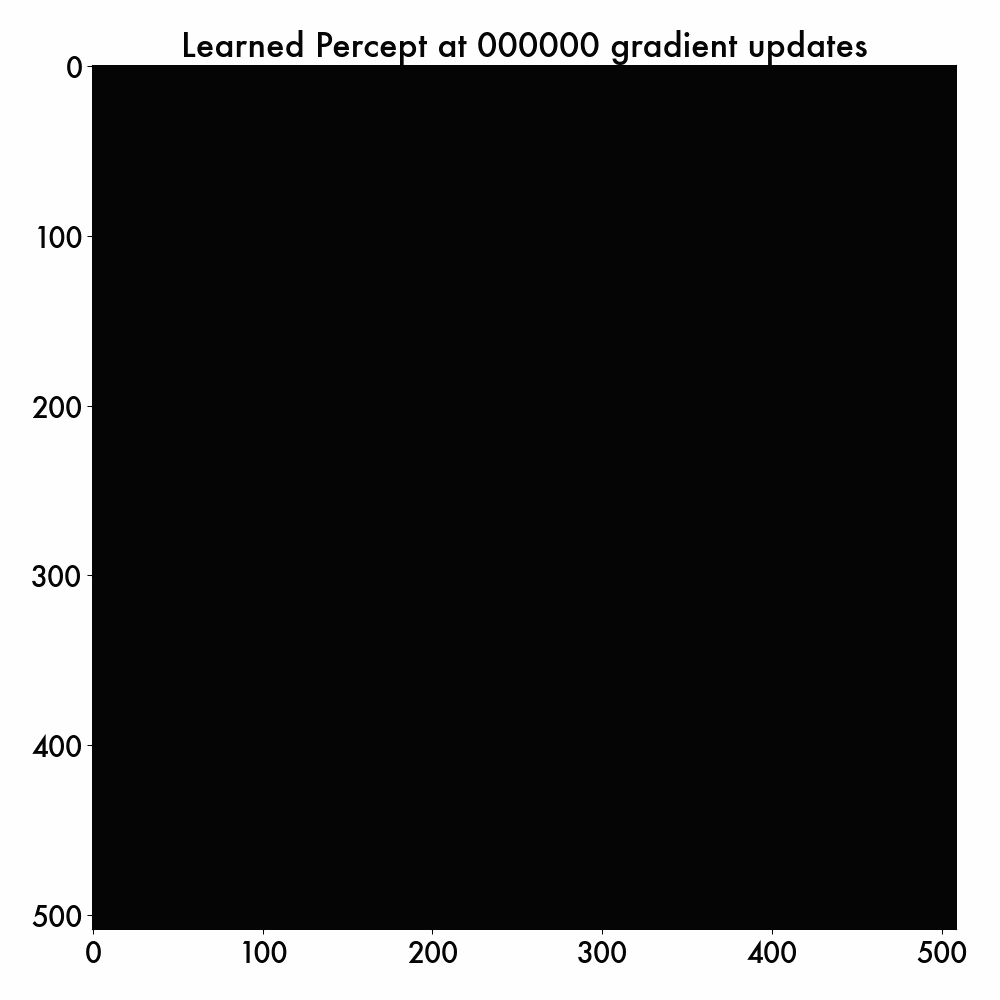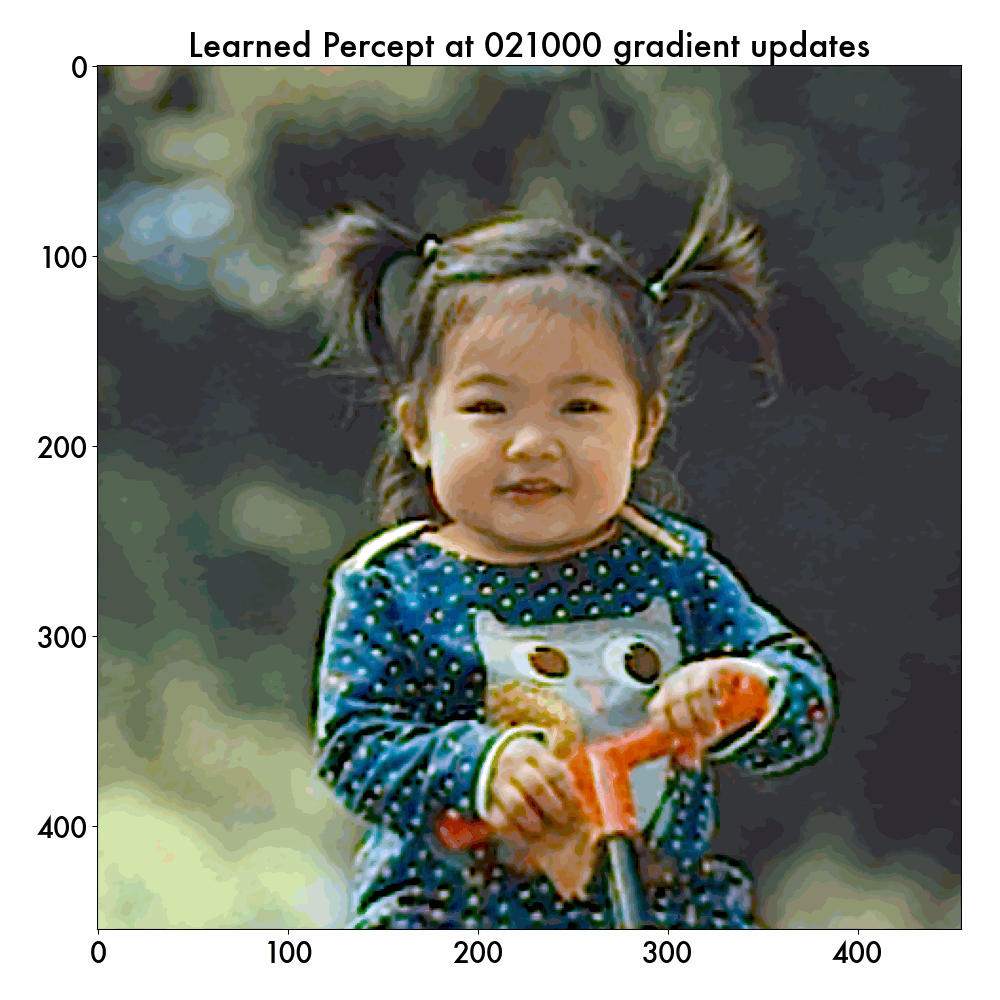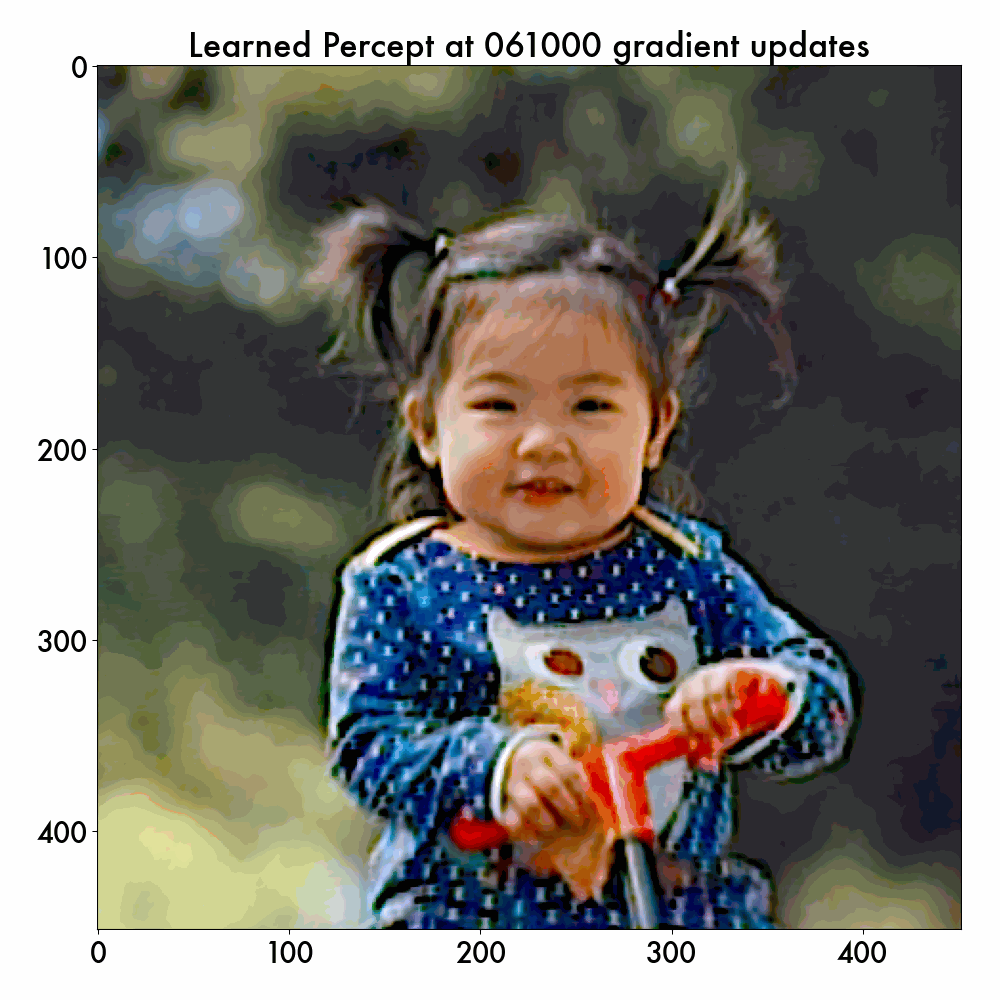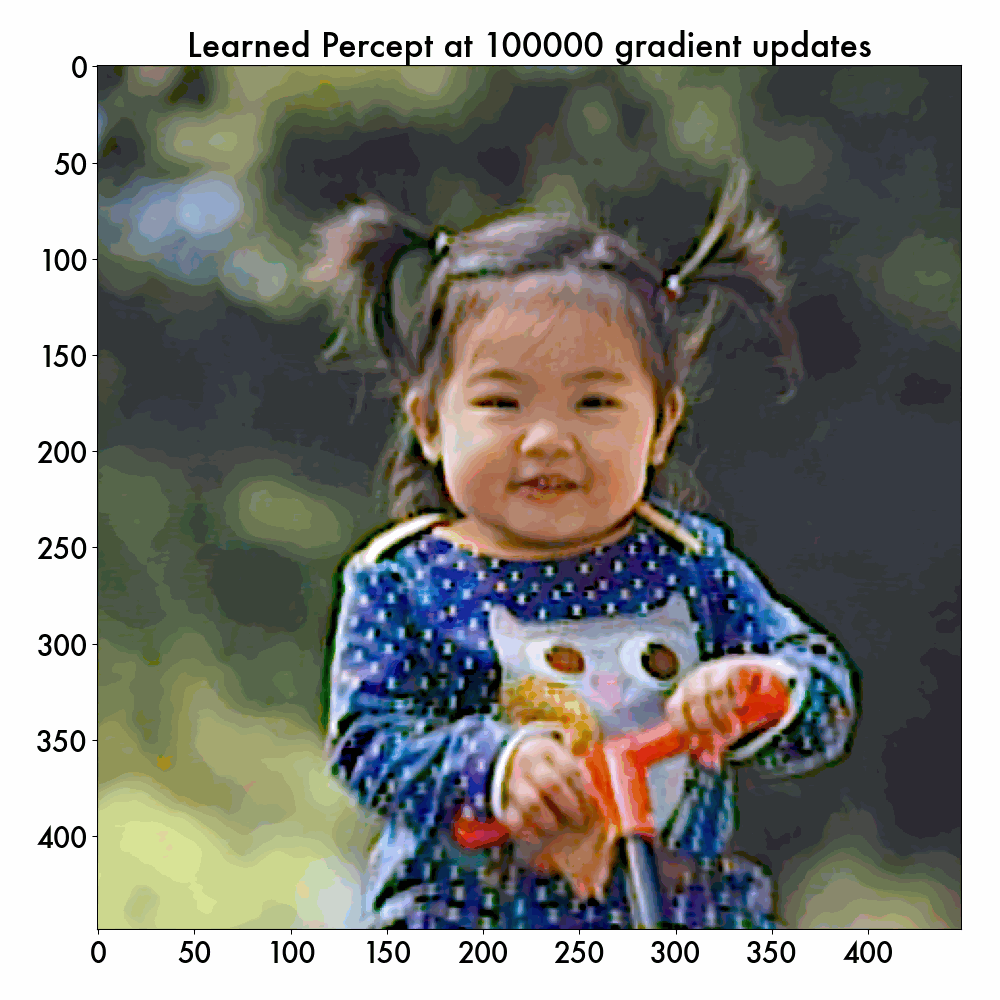
Note that the cortex model never sees this sRGB test image (as only hyperspectral images are used for training), but it successfully learns to generate the smooth internal percept in color. The reason why this percept wobbles a bit is because the cortex continuously updates the inferred cell positions – what’s important is the general trend that the spatial warping is correctly filtered out.
4. Conclusion
In this tutorial, we demonstrated how to train the cortex model from scratch, and visualize the learned internal percepts.